智能摘要
文章讨论了在构建RAG(检索增强生成)知识库问答系统时的关键策略与优化方法。虽然低代码平台如Dify、Coze提供了便捷的配置方式,但在企业级场景中,其问答精准度往往只能达到50、60分,难以满足高要求。文章分别介绍了知识提取、分块、嵌入、存储与索引、检索、生成与效果评估各环节中的技术和最佳实践。重点指出,需通过多个细致优化步骤提升系统性能,并推荐结合文档实际情况和生成目标选择合适的处理方式,持续关注新兴技术,如Self-RAG,以实现更高质量的知识库问答系统。
— 此摘要由AI生成仅供参考。
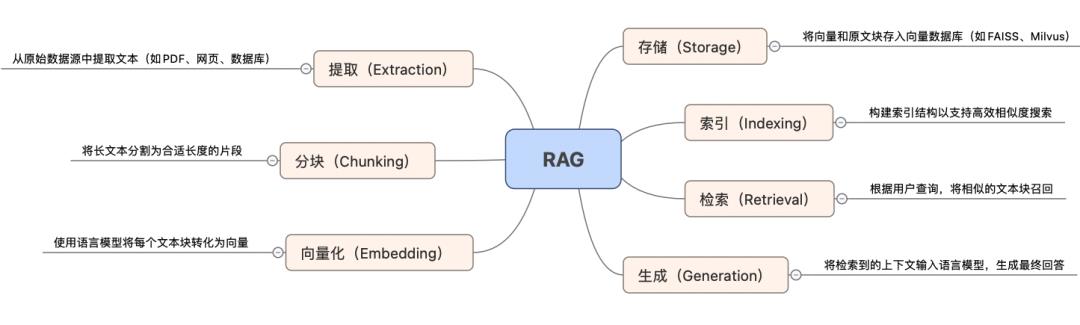

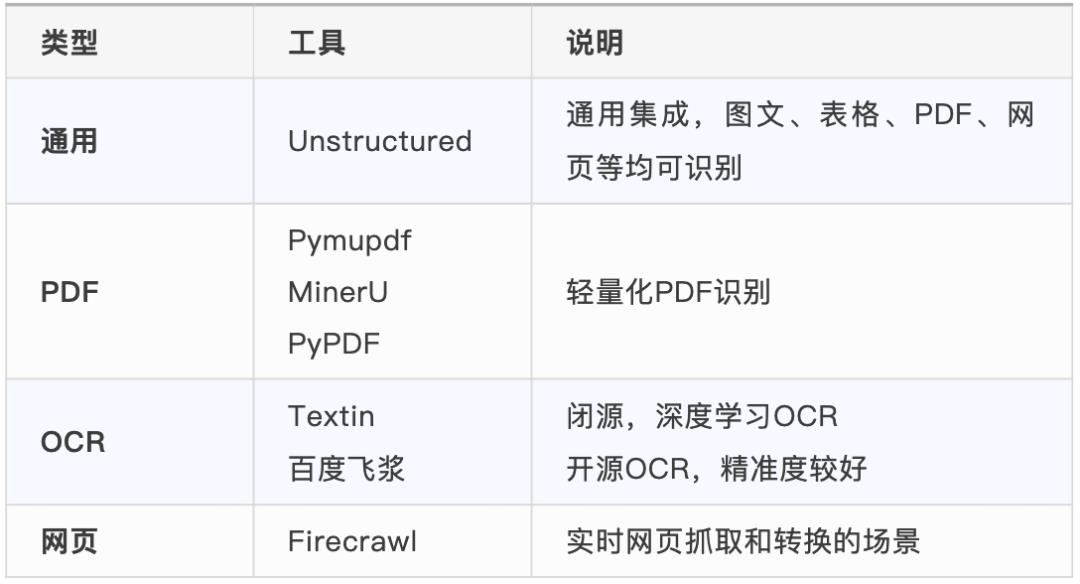


-
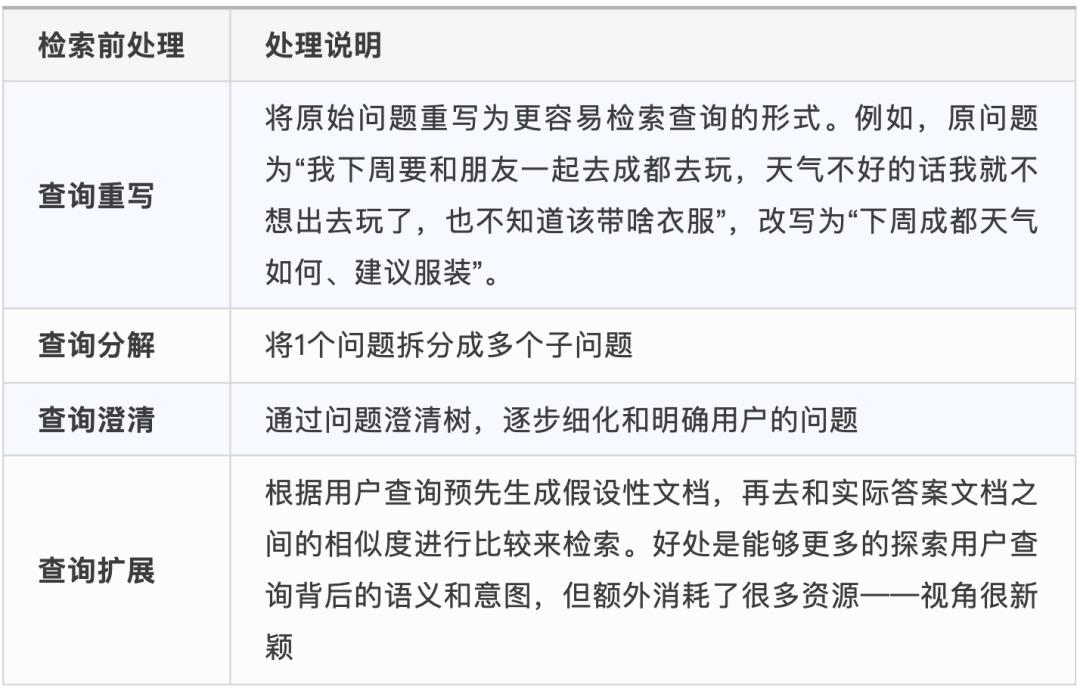
混合生成父子文本块:先生成粒度较大的文本块,再切分成更小的子文本块,父子文本块用ID进行映射关联。在检索阶段,先检索到子文本块,再通过ID找出其父文本块,从而将2者一并传递给大模型,提升更加丰富和准确的回答。 -
生成文本块元数据:分块后同步为该文本块生成对应的元数据(如标题、页码、创建时间、文件名等),从而在检索时,能够结合元数据作为过滤器来更高效进行检索(该功能目前Dify v1.1.0版本已经开始支持做配置了) -
生成摘要+细节文本块:类似于父子关系,摘要则是由粗及浅,为文档生成概要性摘要信息,再将摘要和细节文本块关联起来 -
生成递归型多层级索引:类似于父子、摘要+细节,递归型则是划分了更多层级的索引树,自上而下是逐渐由粗到细的信息量
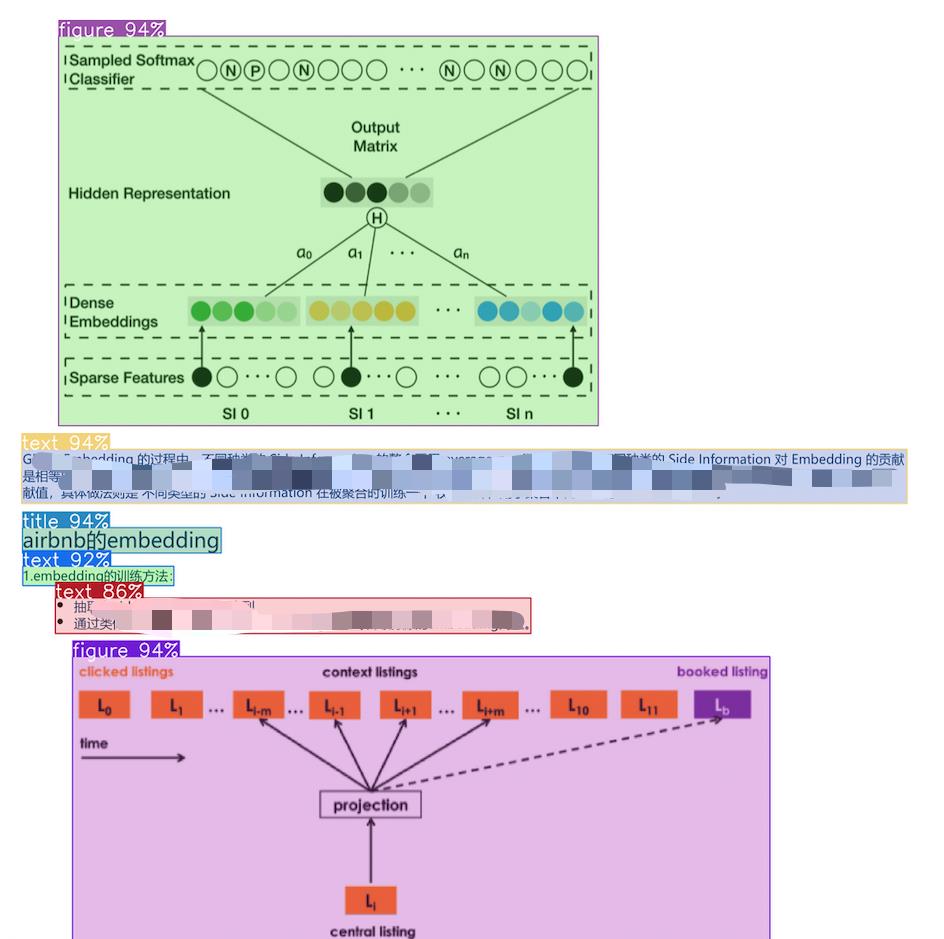
1. 稠密嵌入是一种将离散符号(如词、句子、用户、物品等)映射到低维连续向量空间 中的表示方法。在这个向量中,大部分元素都是非零的实数 ,每个维度都隐式地表达某种语义或特征。
2. 稀疏嵌入是一种将数据映射到高维向量空间 中的表示方法,其中大多数维度的值为0,只有少数维度有非零值 。
-
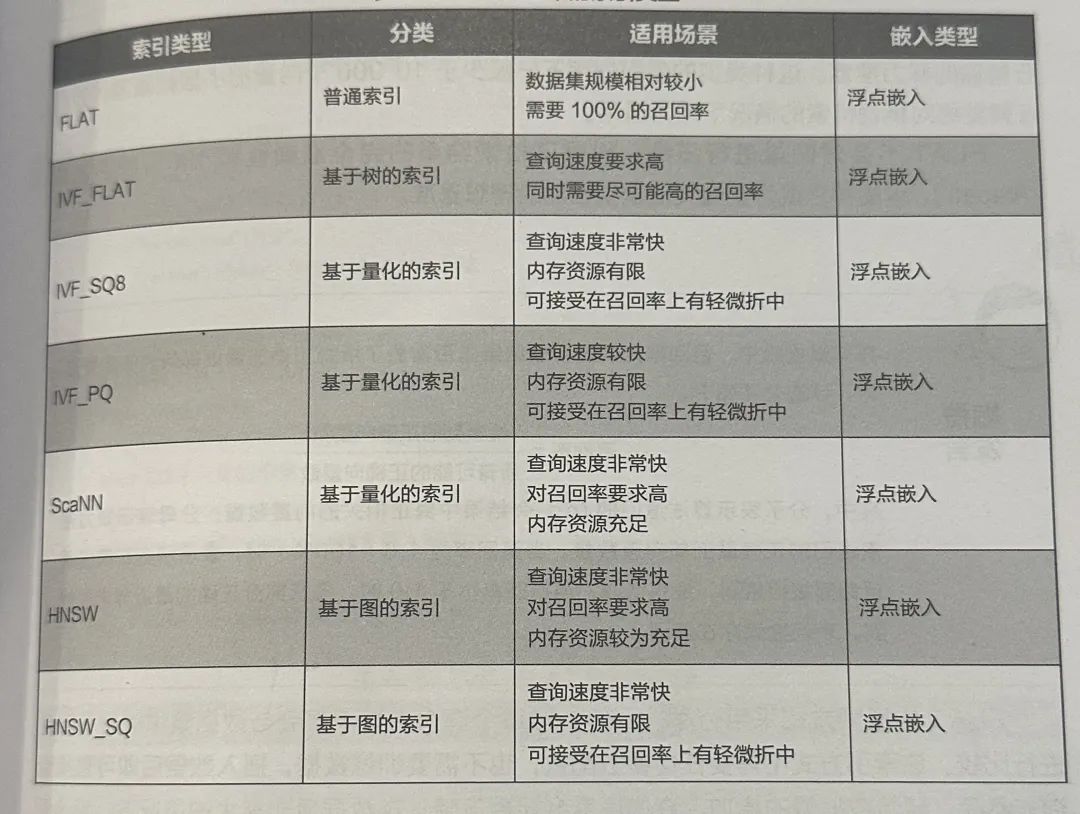
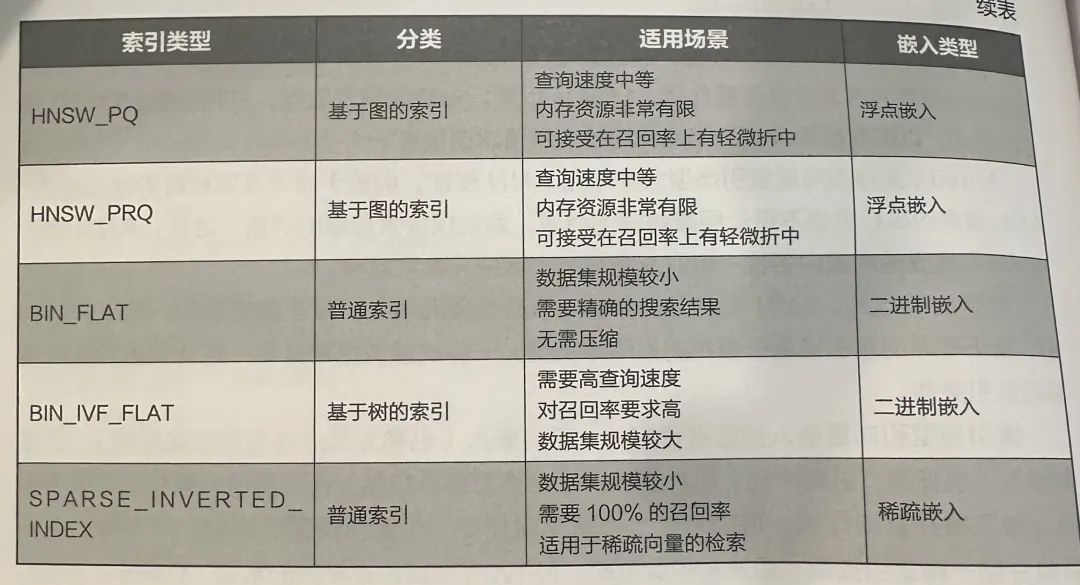
FLAT精确搜索:对所有数据进行暴力性遍历,当然只适合小批量数据啦 -
IVF_FLAT倒排文件索引+精确搜索:将向量数据划分为若干个簇,计算查询向量与每个簇中心的距离,找出相似度最高的n个簇,再在这些簇里面检索目标向量。就像你要找到「猫」在哪里,先快速找到「动物类」的簇在哪里。 -
HNSW基于图结构的近似最近邻搜索:目前性能最好的ANN(近似最近邻搜索)算法之一,它通过构建一个多层导航图(如顶层、中层、底层),不同层级的密度逐步变大,让查询时能像坐地铁一样“跳跃式”地快速接近目标点。目前Dify中Weaviate的默认索引方式就是HNSW。

|
|
|
|---|---|
|
|
|
|
|
|


|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|
|
|
|
|
|
|

文章评论
分块这块挺关键的,之前踩过坑。
@灵动世纪 分块确实容易踩坑,调参调到头秃
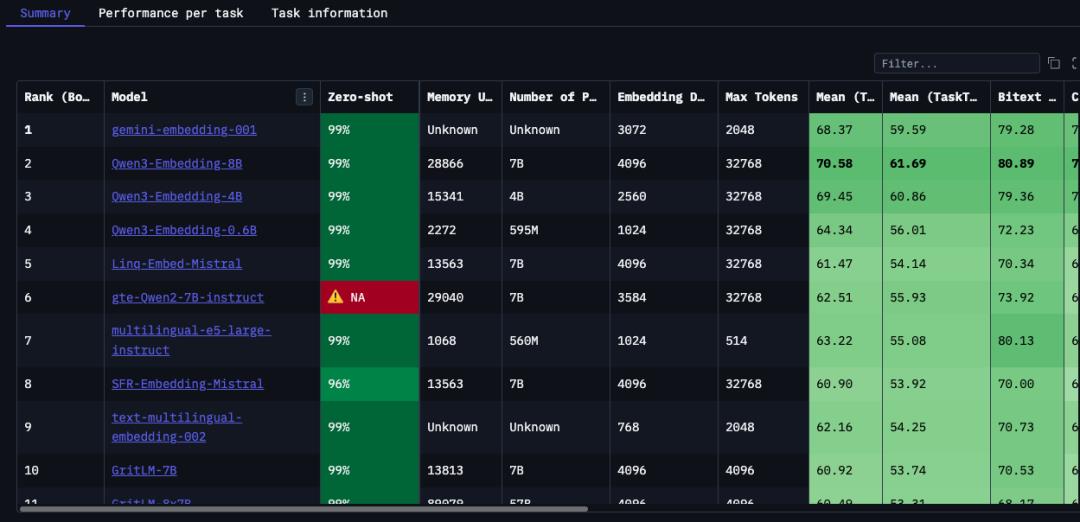
嵌入模型排名阿里这么强?
RAG落地真不只是拖拽那么简单
评估那块太真实了,客户给的测试集根本覆盖不了真实场景。
@白露饮 测试集和真实场景的差距往往是最大的坑。
OCR在金融场景真有用
@琳琳 金融单据识别全靠它救命