写在前面:为什么 MCP 不是一个技术标准,而是一次架构范式转移 2024年底,Anthropic 推出了 Model Context Protocol(MCP),一个看似轻量级却暗藏巨大野心的开放协议。当我第一次深入阅读 MCP 的规范文档时,感受到的不是又一个 API 标准的诞生,而是一种与 REST、GraphQL 一脉相承的架构思维进化——只是这一次,主角从人机交互变成了 AI-系统交互。 如果说 REST 解决了 Web 服务的资源表述问题,GraphQL 解决了查询灵活性问题,那么 MCP 要回答的是:…

智能摘要 本文全面梳理 LLM 模型路由系统的技术原理与工业实践。核心探讨五大技术路线:规则路由、分类器路由、级联推理、强化学习路由与生成式路由,每一条均有 FrugalGPT、RouteLLM 等顶会论文论证。详细对比火山引擎 Auto Mode 与 OpenRouter 两种代表性的跨模型/跨供应商路由方案,给出分层路由 + 质量-成本联合优化的最佳实践架构。 — 此摘要由AI生成仅供参考。 LLM 模型路由系统深度调研:原理、论文与工业实践 一、概述 随着大语言模型(LLM)的数量和种类爆发式增长,如何自动选…
AgentScope 是阿里巴巴通义实验室开源的生产级 AI Agent 框架,截至 2026 年 7 月 GitHub 已获约 22.6k Stars、2.3k Forks。本文基于 AgentScope 2.0 实际源码(main 分支)进行深度架构分析。
A2A (Agent-to-Agent) 协议详解 A2A 是一个开放协议,让不同框架、不同厂商、不同服务器上运行的 AI Agent 能够互相通信和协作。当前版本 v1.0.0。 一、原始内容概述 1.1 什么是 A2A A2A(Agent-to-Agent,代理间通信协议)是一个开放协议,由 Google 贡献给 Linux Foundation 作为开源项目,Apache 2.0 许可。当前版本为 v1.0.0(正式发布版)。 它的核心使命是:让不同框架、不同厂商、不同服务器上运行的 AI Agent 能够像…
A2UI (Agent-to-User Interface) 协议详解 A2UI 是一个开放的协议标准,让 AI Agent 能够安全地向客户端发送丰富的交互式用户界面。Agent 发送声明式 JSON 描述 UI 的意图,客户端使用自己的原生组件库渲染出来。 一、原始内容概述 1.1 什么是 A2UI A2UI(Agent-to-User Interface)是一个开放的协议标准,由 Google 主导开发,CopilotKit 及开源社区共同贡献,Apache 2.0 许可。它的核心使命是:让 AI Agent…

Hermes-Agent 源码架构分析报告 1. 项目总览 指标 数值 Python 文件总数(排除测试) 822 Python 代码总行数(排除测试) ~589,563 核心模块数 9 模型提供方(providers) 29 个插件目录 内置技能(skills) 18 个分类目录 可选技能(optional-skills) 19 个分类目录 支持的消息平台 20+ 核心模块:agent / hermes_cli / plugins / gateway / tools / acp_adapter / tui_gat…
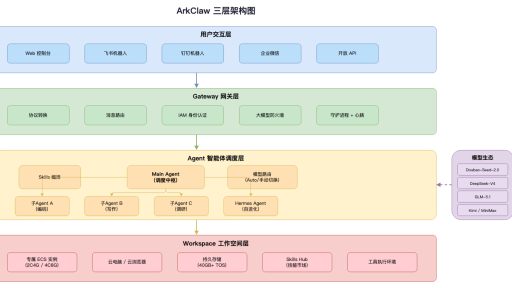
概述 ArkClaw 是火山引擎(字节跳动)于 2026 年 3 月推出的云 SaaS 版本,基于开源项目 OpenClaw("龙虾")构建。本报告从架构设计、安全体系、运行机制、多智能体、飞书集成及企业版等维度,全面剖析 ArkClaw 的技术内核。 产品定位与核心架构 ArkClaw 采用 Gateway-Agent-Workspace 三层架构,是开源 OpenClaw 的云原生 SaaS 封装。 Gateway 网关层 Gateway 层是所有用户请求的入口,负责协议转换与消息路由,核心职责包括: 协议转换…
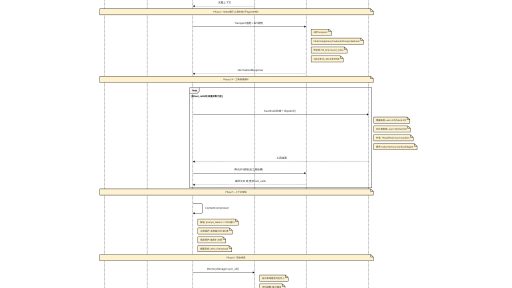
Hermes Agent 核心策略全景 Hermes Agent 核心策略全景 1. 智能体分配策略 策略类型 触发条件 关键参数 行为描述 用户视角触发例子 子智能体委派 模型调用 delegate_task 工具 最大并发: 3, 深度: 1层, 迭代上限: 50 ThreadPoolExecutor 并行子 AIAgent,每个独立迭代预算,默认工具集 [terminal, file, web] 你说"帮我同时调研3个竞品",助手派出3个小助手分头去查,各自独立工作 后台审阅 每回合结束后自动 spawn m…
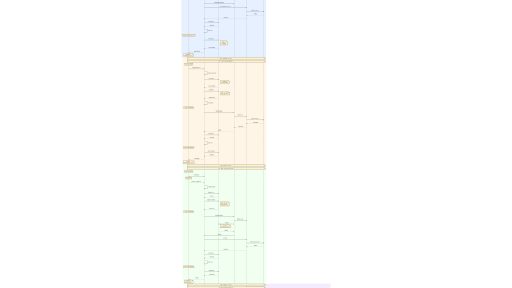
本文档展示了用户与 AI Agent 在不同交互场景下的完整时序流程,涵盖 6 个核心参与主体,并按照「计划生成 → 工具调用链路 → 结果生成与返回」三阶段进行拆解。 参与主体 User(用户):消息、语音、多模态输入的发起者 Agent(智能体工程):编排、路由、决策的核心调度层 LLM(大模型):意图识别、内容生成、语音合成等 AI 能力提供者 Agent Skills(技能系统):封装特定领域能力的模块 MCP(中间层):模型上下文协议,统一管理外部工具调用 Tools(外部工具):各类第三方服务与 API…
一、概述 SSML(Speech Synthesis Markup Language,语音合成标记语言)是由 W3C 制定的标准 XML 标记语言,用于控制文本转语音(TTS)的输出。通过 SSML 标签,开发者可以精确控制合成语音的语速、音调、音量、停顿、发音方式、朗读风格等。 LaTeX 公式朗读则是在此基础上的能力延伸——将数学公式以自然语音输出,让 TTS 能够"读懂"数学表达式并正确朗读。 SSML 标准版本:SSML 1.0(2004)→ SSML 1.1(2010) LaTeX 朗读本质:将公式解析后…